Target Audience
AI developers, Product managers
Techniques
Human evaluation, Automated metrics, Task-specific testing, A/B testing
Evaluation Goals
Quality, Safety, Consistency, Performance
Explore essential techniques for evaluating Large Language Model (LLM) responses, crucial for high-quality AI products. Coverage includes human evaluation, automated metrics, task-specific assessments, and A/B testing. The importance of continuous evaluation is emphasized, addressing challenges like subjectivity and bias detection. Best practices include combining multiple techniques, using diverse test sets, and implementing ethical guidelines. The post introduces popular evaluation tools such as Snorkel, Ragas, AWS tools, and DeepEval. Rigorous evaluation plays a critical role in harnessing LLM potential while mitigating risks and building user trust. The need for evolving evaluation standards is highlighted as LLM capabilities advance, stressing transparent reporting and incorporating real-world performance data.
In the rapidly evolving landscape of artificial intelligence, Large Language Models (LLMs) have become integral to many products and services. From chatbots to content generation tools, LLMs are powering a new wave of AI-driven applications. However, with great power comes great responsibility. As developers and product managers, it’s crucial to implement robust evaluation techniques to ensure the quality, reliability, and safety of LLM-generated content.
Why Evaluate LLM Responses?
Evaluating LLM responses is of paramount importance for several reasons. First and foremost, it ensures quality assurance, guaranteeing that the AI-generated content meets the standards expected by users and stakeholders. It also serves as a safety measure, helping to prevent the generation of harmful, biased, or inappropriate content. Consistency is another key factor, as evaluation helps maintain a uniform user experience across different interactions.
“The difference between a good AI product and a great one often lies in the rigour of its evaluation process.” — AI Product Manager’s Handbook
Moreover, evaluation enables performance tracking, allowing for continuous improvement of the model and prompts. Perhaps most importantly, it builds user trust. By demonstrating a commitment to quality and safety, we encourage wider adoption and use of AI systems.
Key Evaluation Techniques
1. Human Evaluation
Human evaluation remains one of the most reliable methods for assessing LLM outputs. It involves having human raters review and score the model’s responses based on predefined criteria. This method excels at assessing subjective qualities like creativity and contextual appropriateness, and can catch nuanced errors that automated systems might miss.
A typical human evaluation process might look like this:
- Define clear evaluation criteria (e.g., relevance, accuracy, tone)
- Create a diverse set of test prompts
- Generate responses using the LLM
- Have multiple raters score each response
- Analyze the results to identify strengths and weaknesses
2. Automated Metrics
Automated metrics provide a quick and scalable way to evaluate LLM responses. While they may not capture all aspects of quality, they can offer valuable insights and flag potential issues. Here’s a table of common automated metrics:
| Metric | Description | Use Case |
|---|---|---|
| BLEU | Measures similarity to reference texts | Translation, summarization |
| ROUGE | Assesses overlap with reference summaries | Summarization |
| Perplexity | Measures how well the model predicts a sample | General language modelling |
| Embedding Similarity | Compares semantic similarity using embeddings | Semantic coherence |
The main advantages of automated metrics are their speed, scalability, and consistency. They’re particularly useful for continuous monitoring of model performance.
3. Task-Specific Evaluation
For many applications, it’s crucial to evaluate LLM responses in the context of specific tasks or use cases. This involves creating test sets that closely mimic real-world scenarios and assessing performance on these tasks. For instance, when evaluating a customer support chatbot, you might assess the LLM’s responses based on:
- Accuracy of information provided
- Appropriateness of tone
- Ability to handle edge cases
- Escalation to human support when necessary
4. Prompt Response Evaluation Using PyTest
Automated testing frameworks like PyTest can be invaluable for systematically evaluating LLM responses. Here’s a simple example of how you might use PyTest to evaluate prompt responses:
Create this block using “/syntaxhighlighter”
import pytest
from your_llm_module import generate_response
def test_prompt_response():
prompt = "What is the capital of France?"
expected_keywords = ["Paris", "city", "France", "capital"]
response = generate_response(prompt)
assert all(keyword.lower() in response.lower() for keyword in expected_keywords), \
f"Response '{response}' does not contain all expected keywords: {expected_keywords}"
assert len(response.split()) >= 10, \
f"Response '{response}' is too short. Expected at least 10 words."
assert not any(bad_word in response.lower() for bad_word in ["inappropriate", "offensive"]), \
f"Response '{response}' contains inappropriate language."
This test checks for the presence of expected keywords, ensures a minimum response length, and screens for inappropriate language. By expanding on these basic checks, you can create sophisticated evaluation criteria tailored to your specific use case.
5. A/B Testing
A/B testing involves comparing two versions of a prompt or model to see which performs better in real-world conditions. This can be particularly useful when fine-tuning models or optimizing prompts.
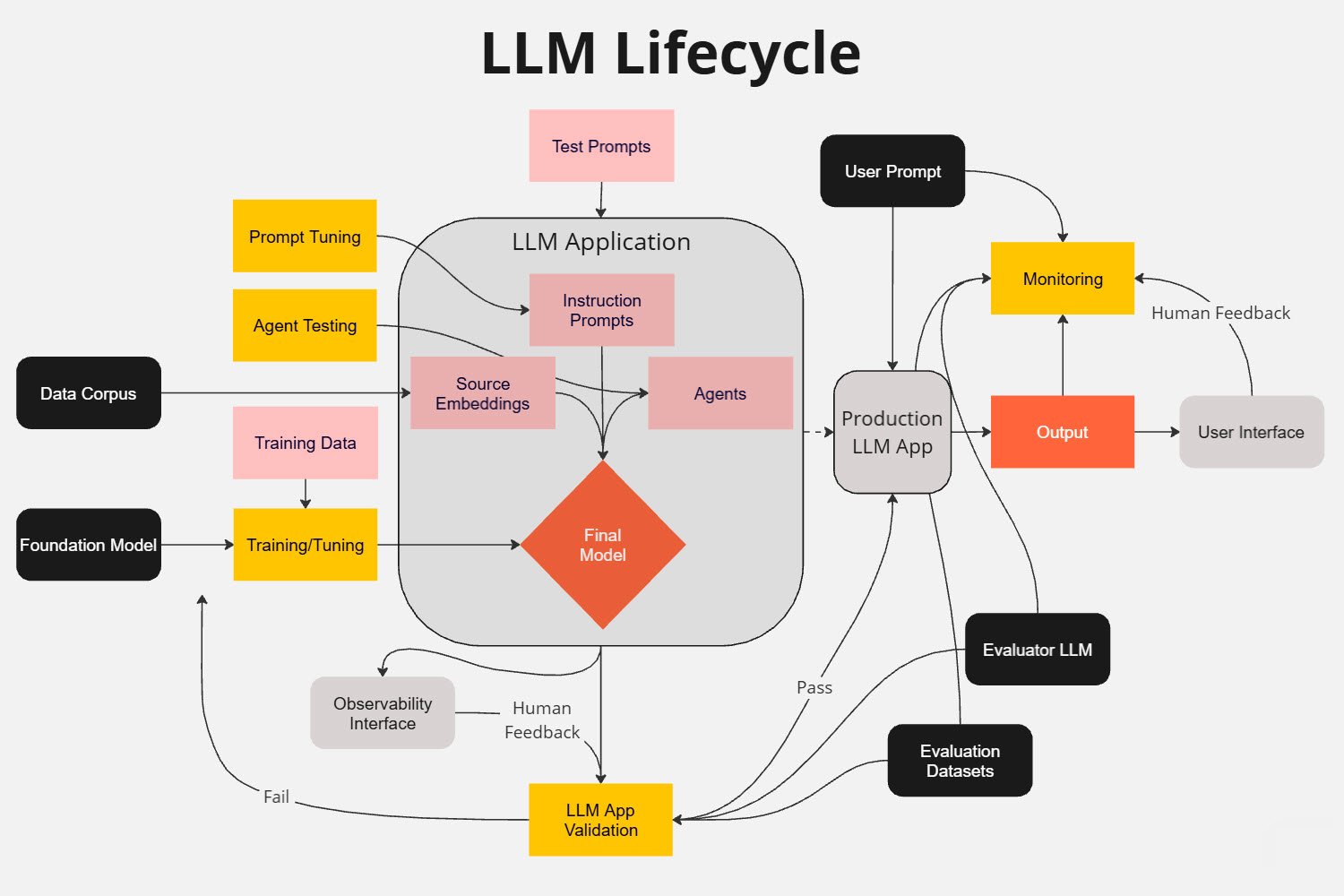
Popular Tools for Evaluation
As the field of LLM evaluation continues to grow, a number of powerful tools have emerged to assist developers and researchers in assessing model performance. These tools range from open-source libraries to comprehensive cloud-based solutions, each offering unique features and capabilities to streamline the evaluation process.
In this section, we’ll explore four popular tools that are making waves in the LLM evaluation landscape. Each of these tools brings its own strengths to the table, catering to different aspects of the evaluation process and various use cases.
Snorkel
Snorkel is a powerful platform for programmatically building and managing training data. While originally designed for traditional machine learning tasks, Snorkel has found significant application in LLM evaluation. Its data labeling capabilities are particularly useful for creating large-scale evaluation datasets quickly and efficiently.
Snorkel’s labeling functions allow users to encode domain expertise and heuristics, which can be especially valuable when evaluating LLMs in specialized domains. By leveraging these functions, teams can rapidly generate labeled datasets for both training and evaluation, significantly speeding up the iteration cycle in LLM development and fine-tuning.
Ragas
Ragas is an open-source framework specifically designed for evaluating Retrieval Augmented Generation (RAG) systems, which are increasingly common in LLM applications. Ragas provides a suite of metrics and tools to assess various aspects of RAG performance, including relevance, faithfulness, and context precision.
One of Ragas’ strengths is its ability to evaluate not just the final output of a RAG system, but also the intermediate steps of retrieval and generation. This granular approach allows developers to pinpoint exactly where their systems might be falling short, whether in the retrieval of relevant information or in the generation of responses based on that information.
AWS Evaluation Tools
Amazon Web Services (AWS) offers a range of tools and services that can be leveraged for LLM evaluation as part of its broader AI and machine learning ecosystem. While not exclusively focused on LLM evaluation, services like Amazon SageMaker provide robust capabilities for model deployment, monitoring, and evaluation at scale.
AWS also offers solutions like Amazon Comprehend for natural language processing tasks, which can be useful in evaluating certain aspects of LLM performance. The cloud-based nature of these tools makes them particularly suitable for large-scale evaluations and for teams already invested in the AWS ecosystem.
DeepEval
DeepEval is an open-source Python library designed to simplify the process of evaluating LLMs and other deep learning models. It provides a flexible framework for defining custom evaluation metrics and running comprehensive evaluations across multiple models and datasets.
One of DeepEval’s key features is its ability to integrate with popular deep learning frameworks and to support a wide range of evaluation tasks, from simple classification to more complex natural language understanding tasks. Its modular design allows developers to easily extend its functionality to suit their specific evaluation needs.
Challenges in LLM Evaluation
While these techniques and tools provide valuable insights, evaluating LLM responses comes with its own set of challenges. Subjectivity is a major factor, as many aspects of language quality are context-dependent and open to interpretation. The diversity of possible responses can make it difficult to define “correct” outputs, and evaluating the model’s grasp of context and nuance can be complex.
Bias detection is another ongoing challenge. Identifying and quantifying various forms of bias in model outputs requires careful consideration and often specialized techniques. Furthermore, as LLM capabilities continue to advance, evaluation criteria need to evolve as well, requiring evaluators to stay up-to-date with the latest developments in the field.
Best Practices for LLM Evaluation in Product Development
When integrating LLM evaluation into your product development process, consider the following best practices:
- Combine multiple techniques for a comprehensive assessment
- Implement continuous evaluation throughout your product’s lifecycle
- Use diverse test sets that represent a wide range of use cases
- Clearly communicate evaluation methods and results to stakeholders
- Include ethical guidelines in your evaluation criteria
- Establish mechanisms to incorporate user feedback and real-world performance data
- Keep track of changes in model versions, prompts, and evaluation criteria
By following these practices, you can ensure a robust evaluation process that contributes to the development of high-quality AI-powered products.
Conclusion
Evaluating LLM responses is a critical aspect of building high-quality AI-powered products. By implementing a robust evaluation framework that combines human insight, automated metrics, and task-specific assessments, you can ensure that your LLM-driven features meet the needs and expectations of your users.
Remember, evaluation is not a one-time task but an ongoing process. As LLM technology continues to advance, so too should our methods for assessing and improving their performance. By staying committed to rigorous evaluation and leveraging the powerful tools available, we can harness the full potential of LLMs while mitigating risks and building user trust.
What evaluation techniques or tools have you found most effective in your LLM projects? Share your experiences and insights in the comments below!
Appendix
While these techniques and tools provide valuable insights, evaluating LLM responses comes with its own set of challenges. Subjectivity is a major factor, as many aspects of language quality are context-dependent and open to interpretation. The diversity of possible responses can make it difficult to define “correct” outputs, and evaluating the model’s grasp of context and nuance can be complex.
All about horses 4
While these techniques and tools provide valuable insights, evaluating LLM responses comes with its own set of challenges. Subjectivity is a major factor, as many aspects of language quality are context-dependent and open to interpretation.
All about dogs 4
While these techniques and tools provide valuable insights, evaluating LLM responses comes with its own set of challenges. Subjectivity is a major factor, as many aspects of language quality are context-dependent and open to interpretation.
Take care of them 4
Daily attention 5
While these techniques and tools provide valuable insights, evaluating LLM responses comes with its own set of challenges. Subjectivity is a major factor, as many aspects of language quality are context-dependent and open to interpretation.
Specific foods 5
While these techniques and tools provide valuable insights, evaluating LLM responses comes with its own set of challenges. Subjectivity is a major factor, as many aspects of language quality are context-dependent and open to interpretation.
Washing them too 5
While these techniques and tools provide valuable insights, evaluating LLM responses comes with its own set of challenges. Subjectivity is a major factor, as many aspects of language quality are context-dependent and open to interpretation.
This article is part of our series on AI product development best practices. More articles to come. A zigzag path just needs a start.