
Target Audience
AI developers, Product managers
Techniques
Human evaluation, Automated metrics, Task-specific testing, A/B testing
Evaluation Goals
Quality, Safety, Consistency, Performance
Explore essential techniques for evaluating Large Language Model (LLM) responses, crucial for high-quality AI products. Coverage includes human evaluation, automated metrics, task-specific assessments, and A/B testing. The importance of continuous evaluation is emphasized, addressing challenges like subjectivity and bias detection. Best practices include combining multiple techniques, using diverse test sets, and implementing ethical guidelines. The post introduces popular evaluation tools such as Snorkel, Ragas, AWS tools, and DeepEval. Rigorous evaluation plays a critical role in harnessing LLM potential while mitigating risks and building user trust. The need for evolving evaluation standards is highlighted as LLM capabilities advance, stressing transparent reporting and incorporating real-world performance data.
A few weeks ago, we released prompt caching for Claude, which makes this approach significantly faster and more cost-effective. Developers can now cache frequently used prompts between API calls, reducing latency by > 2x and costs by up to 90% (you can see how it works by reading our prompt caching cookbook).
Only use H3 and smaller for headings
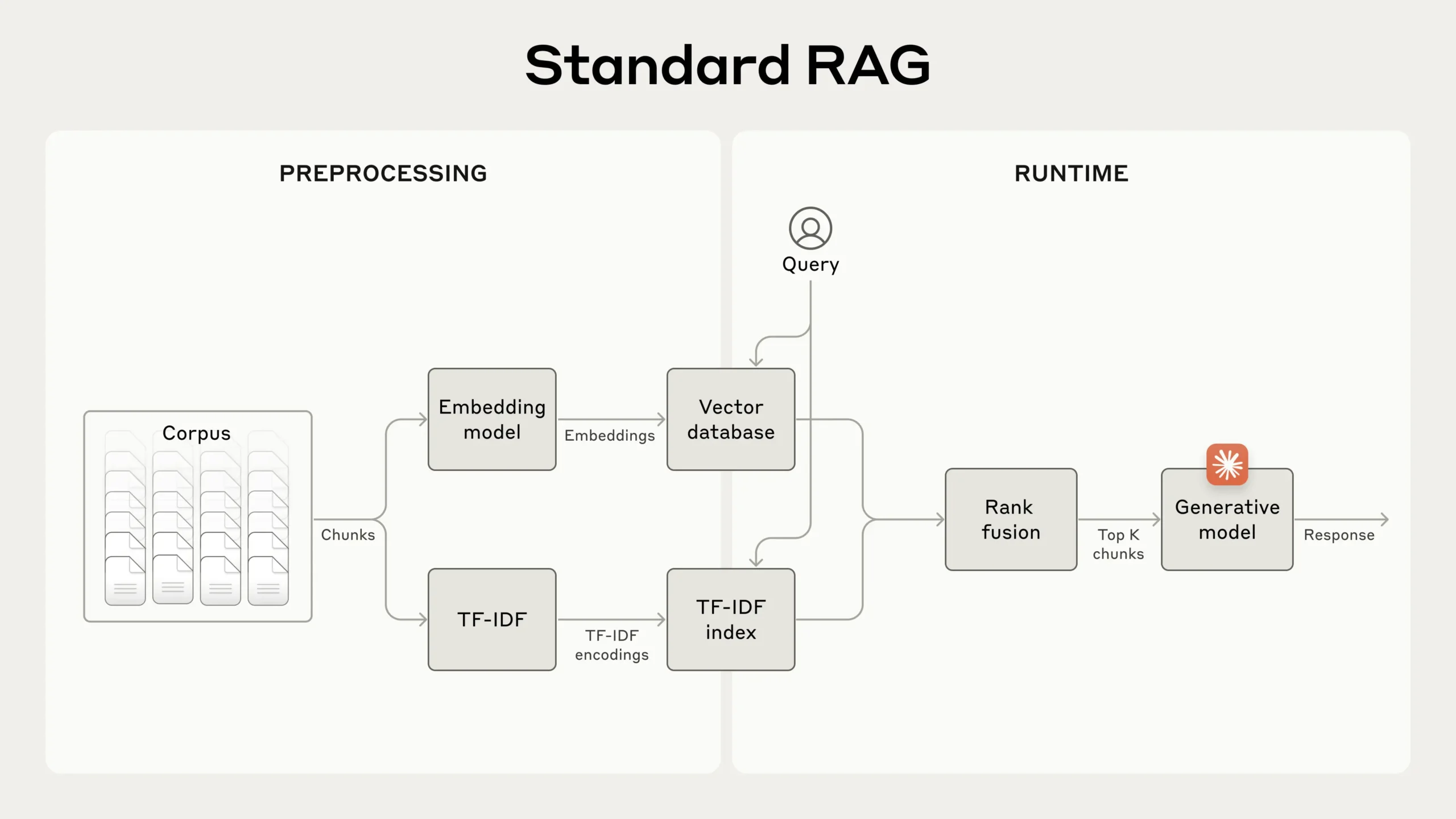
For larger knowledge bases that don’t fit within the context window, RAG is the typical solution. RAG
Here’s how BM25 can succeed where semantic embeddings fail: Suppose a user queries “Error code TS-999” in a technical support database. An embedding model might find content about error codes in general, but could miss the exact “TS-999” match. BM25 looks for this specific text string to identify the relevant documentation.
Lists are nicely spaced H4
RAG solutions can more accurately retrieve the most applicable chunks by combining the embeddings and BM25 techniques using the following steps:
- Chunk boundaries: Consider how you split your documents into chunks. The choice of chunk size, chunk boundary, and chunk overlap can affect retrieval performance.
- Embedding model: Whereas Contextual Retrieval improves performance across all embedding models we tested, some models may benefit more than others. We found Gemini and Voyage embeddings to be particularly effective.
- Custom contextualizer prompts: While the generic prompt we provided works well, you may be able to achieve even better results with prompts tailored to your specific domain or use case (for example, including a glossary of key terms that might only be defined in other documents in the knowledge base).
You can use unordered lists too:
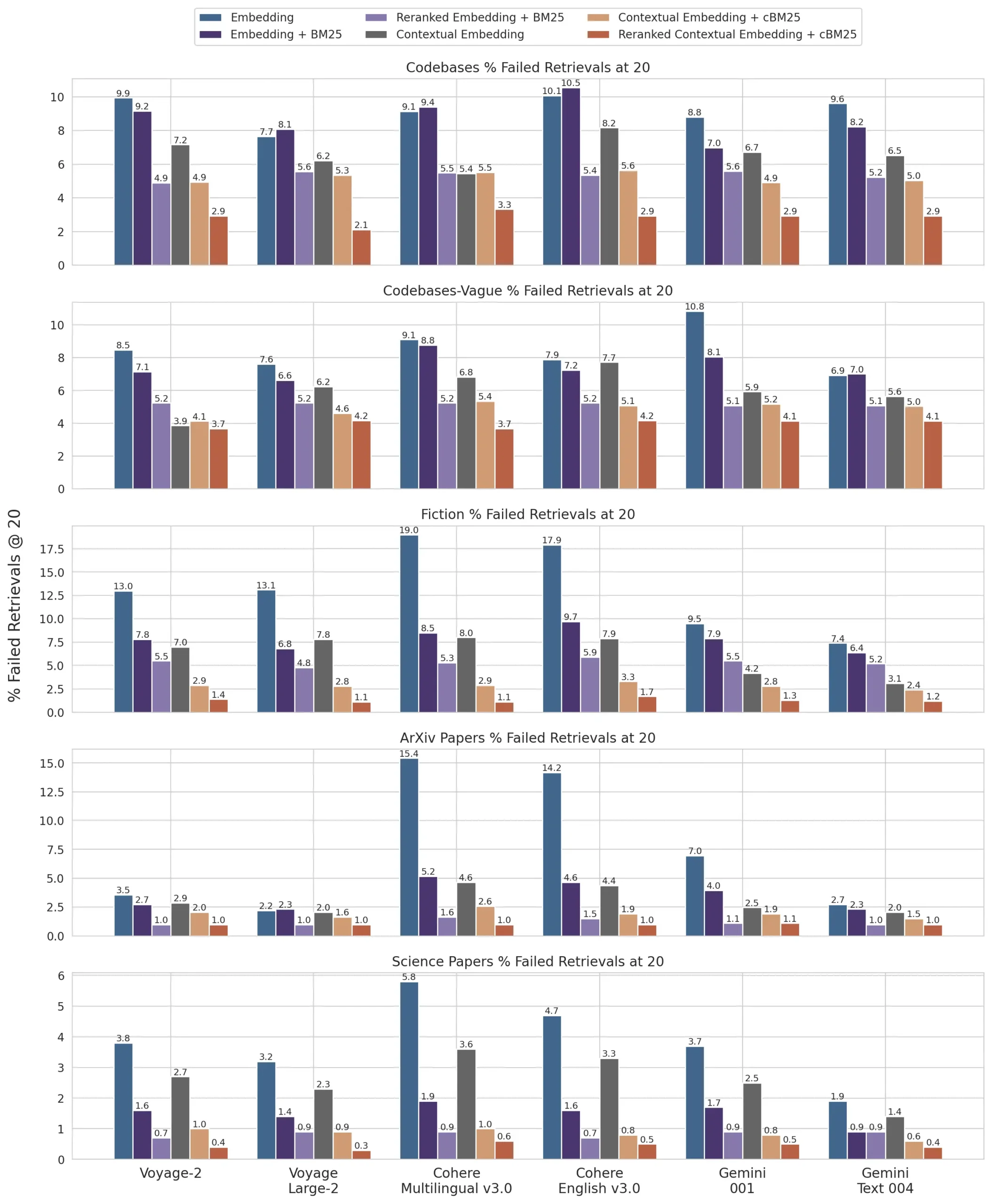
- Contextual Embeddings reduced the top-20-chunk retrieval failure rate by 35% (5.7% → 3.7%).
- Combining Contextual Embeddings and Contextual BM25 reduced the top-20-chunk retrieval failure rate by 49% (5.7% → 2.9%).
Images are nice
There are usually about 200 words in a paragraph, but this can vary widely. Most paragraphs focus on a single idea that’s expressed with an introductory sentence, then followed by two or more supporting sentences about the idea. A short paragraph may not reach even 50 words while long paragraphs can be over 400 words long, but generally speaking they tend to be approximately 200 words in length.
If you’re looking for random paragraphs, you’ve come to the right place. When a random word or a random sentence isn’t quite enough, the next logical step is to find a random paragraph. We created the Random Paragraph Generator with you in mind. The process is quite simple. Choose the number of random paragraphs you’d like to see and click the button. Your chosen number of paragraphs will instantly appear.
A random paragraph can also be an excellent way for a writer to tackle writers’ block. Writing block can often happen due to being stuck with a current project that the writer is trying to complete. By inserting a completely random paragraph from which to begin, it can take down some of the issues that may have been causing the writers’ block in the first place.
Introducing Code Blocks H3
Contextual Retrieval solves this problem by prepending chunk-specific explanatory context to each chunk before embedding (“Contextual Embeddings”) and creating the BM25 index (“Contextual BM25”). Let’s return to our SEC filings collection example. Here’s an example of how a chunk might be transformed:
Use the plugin for a code block H4
# Python 2 only
print "Live PD",
# Backwards compatible (also fastest)
import sys
sys.stdout.write("Breaking Bad")
# Python 3 only
print("Mob Psycho 100", end="")
Use my Gutenberg Code Block Paragraph Pattern H4
Of course, it would be far too much work to manually annotate the thousands or even millions of chunks in a knowledge base. To implement Contextual Retrieval, we turn to Claude. We’ve written a prompt that instructs the model to provide concise, chunk-specific context that explains the chunk using the context of the overall document. We used the following Claude 3 Haiku prompt to generate context for each chunk:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
Tables H3
How this was made: I took a screenshot from Prompt caching with Claude Anthropic and asked Claude to write the markdown table. Then I pasted it in the Gutenberg Editor. I create a class for my tables called “table_like_anthropic_mp” and styled it in Elementor > Custom Code. I also created a Gutenburg pattern called “Table Like Anthropic MP“
Example 1: Using My Gutenberg Pattern
Sometimes you need a paragraph. Please review the screenshot of this table rendered on a webpage. Your task is to create a markdown version of this table. There are 4 columns and 4 rows. Ensure you bold the appropriate text too as per the screenshot. output as a markdown code block. Ensure VALID markdown syntax. I will paste this into the Gutenberg WordPress editor.
| Header 1: My Pattern Table | Header 2 | Header 3 | Header 4 |
|---|---|---|---|
| This Pattern uses a CSS Class • I used Elementor’s Custom Code • It’s only to be used for tables | $3 / MTok | • $3.75 / MTok – Cache write • $0.30 / MTok – Cache read | $15 / MTok |
| It follows Anthropic Styling • Borders was the most difficult • Has font size and spacing too | $15 / MTok | • $18.75 / MTok – Cache write • $1.50 / MTok – Cache read | $75 / MTok |
| Use Gutenberg Options too • Fixed width table cells, bold • Header sections, text alignment | $0.25 / MTok | • $0.30 / MTok – Cache write • $0.03 / MTok – Cache read | $1.25 / MTok |
Remove the Section Header. Sometimes you need a paragraph. Please review the screenshot of this table rendered on a webpage. Your task is to create a markdown version of this table. There are 4 columns and 4 rows. Ensure you bold the appropriate text too as per the screenshot. output as a markdown code block. Ensure VALID markdown syntax. I will paste this into the Gutenberg WordPress editor.
| This Pattern uses a CSS Class • I used Elementor’s Custom Code • It’s only to be used for tables | $3 / MTok | • $3.75 / MTok – Cache write • $0.30 / MTok – Cache read | $15 / MTok |
| It follows Anthropic Styling • Borders was the most difficult • Has font size and spacing too | $15 / MTok | • $18.75 / MTok – Cache write • $1.50 / MTok – Cache read | $75 / MTok |
| Use Gutenberg Options too • Fixed width table cells, bold • Header sections, text alignment | $0.25 / MTok | • $0.30 / MTok – Cache write • $0.03 / MTok – Cache read | $1.25 / MTok |
Example 2: Paste in Markdown and use Class
You can paste in a markdown table, and then just give it the class “table_like_anthropic_mp“. Sometimes you need a paragraph. Please review the screenshot of this table rendered on a webpage. Your task is to create a markdown version of this table. There are 4 columns and 4 rows. Ensure you bold the appropriate text too as per the screenshot. output as a markdown code block. Ensure VALID markdown syntax. I will paste this into the Gutenberg WordPress editor.
| Use case | Latency w/o caching (time to first token) | Latency w/ caching (time to first token) | Cost reduction |
|---|---|---|---|
| Chat with a book (100,000 token cached prompt) [1] | 11.5s | 2.4s (-79%) | -90% |
| Many-shot prompting (10,000 token prompt) [1] | 1.6s | 1.1s (-31%) | -86% |
| Multi-turn conversation (10-turn convo with a long system prompt) [2] | ~10s | ~2.5s (-75%) | -53% |
Sometimes you need a paragraph. Please review the screenshot of this table rendered on a webpage. Your task is to create a markdown version of this table. There are 4 columns and 4 rows. Ensure you bold the appropriate text too as per the screenshot. output as a markdown code block. Ensure VALID markdown syntax. I will paste this into the Gutenberg WordPress editor.
| Claude 3.5 Sonnet • Our most intelligent model to date • 200K context window | Input • $3 / MTok | Prompt caching • $3.75 / MTok – Cache write • $0.30 / MTok – Cache read | Output • $15 / MTok |
| Claude 3 Opus • Powerful model for complex tasks • 200K context window | Input • $15 / MTok | Prompt caching • $18.75 / MTok – Cache write • $1.50 / MTok – Cache read | Output • $75 / MTok |
| Claude 3 Haiku • Fastest, most cost-effective model • 200K context window | Input • $0.25 / MTok | Prompt caching • $0.30 / MTok – Cache write • $0.03 / MTok – Cache read | Output • $1.25 / MTok |
You have included actual ascii bullet points in the table. I thought you would have used markdown syntax. Why have you done this?
Where does this go?
YouTube Block
Here is a youtube block.
The spacing is equal if bounded by paragraphs. Headings above will never be used, it throws it off. Headings below could be used – it throws it off but its understandable. Headings have margins above them as they should have.
Appendix I hello
Below is a1 breakdown of results across2 datasets, embedding providers, use of BM25 in addition to embeddings, use of contextual retrieval, and use of reranking3 for Retrievals @ 20. See Appendix II for the breakdowns for Retrievals @ 10 and @ 5 as well as example questions and answers for each dataset.
Footnotes
- Here is a little footnote ↩︎
- Here is another little footnote ↩︎
- Definitely the last footnote is right here ↩︎