
Tools Used
Anthropic API, Python
Techniques Used
Chunking. Prompt evaluations.
Solution
Python Notebook here.
Upload any .docx file and see corrections in colour.
Corrects writing mistakes that slip past Microsoft Word. Effective in English, German, and Italian. Preserves original meaning, writing style, and document structure. Includes chunking and prompt evaluations.
Built with Claude 3.5 Sonnet via the Anthropic Python API.
The Problem
Surprisingly, Microsoft Word misses many subtle writing mistakes. Pasting paragraph by paragraph into an AI chat is slow and often alters writing style. A better approach was needed: upload a very large Word document and see all corrections at once, with style and meaning preserved and in colour.
This solution provides exactly that: an easy-to-read format showing corrections completely undetected by Microsoft Word. Unlike an AI chat, from the user’s perspective, the corrections appear to be done all in one go.
The proof is in the output: mistakes Word completely missed, now corrected and highlighted in colour—see the full example.

Capabilities at a glance:
- Surprisingly outperforms Microsoft Word‘s capabilities to detect and correct writing mistakes.
- Supports large documents tested up to 100,000 words, approx. 240 pages.
- Multi-language support: Can be used confidently in English, German, French or Italian.
- Preserves semantic meaning, writing style, and document structure.
- Comprehensive testing suite to ensure correction integrity.
Implementation

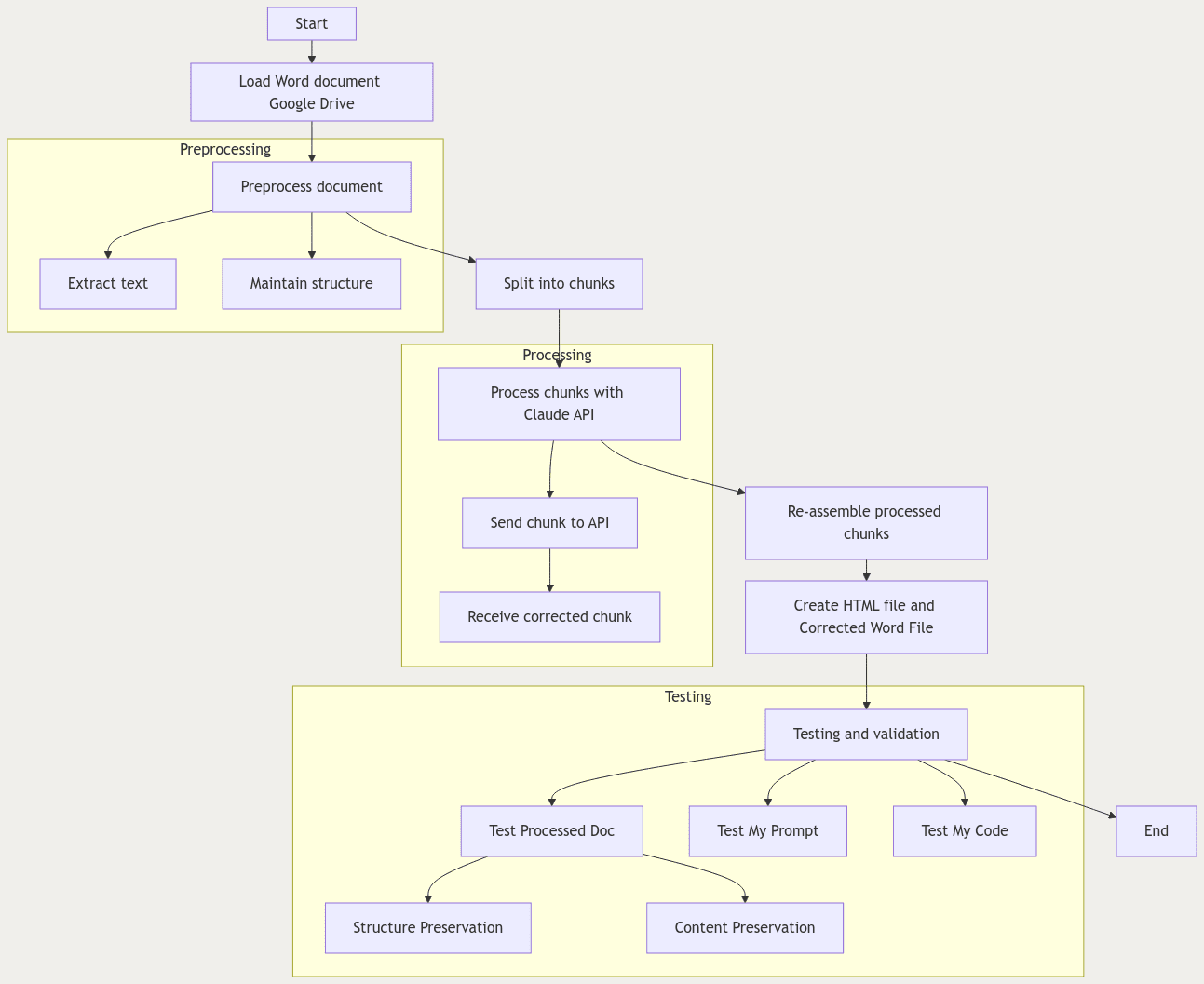
Looking at Figure 2, in essence the Word document is converted into a markdown file and then broken into chunks. Each chunk is sent to Claude along with the instructional prompt to determine and apply corrections. The corrected chunks are assembled into a “processed” markdown file and converted into a webpage (HTML) for “corrections in colour”.
The greatest effort—time well spent—went into developing the three-layer testing approach outlined in the next section.
Rudimentary Testing & Evaluation
Creating this notebook taught me that automated testing with LLMs is the difference between success and failure. You must go slower to go faster.
The test plan was divided into 3 major areas:
- Test Processed Doc: End-to-end testing, verifying code and prompt.
- Test Prompts: Prompt evaluation to ensure responses are as expected (generated test data).
- Test My Code: Traditional functional testing for core code components.
The first two areas incorporate testing Claude’s responses. This might seem like overkill, but it’s essential for three reasons:
- Scale and variability: Manually checking 20 large Word documents isn’t practical—especially in different languages. Thorough testing on one document doesn’t guarantee the same reliability on another when content varies significantly.
- Model flexibility: Switching from Claude 3.5 Sonnet to alternatives like Meta Llama 3.1 or DeepSeek v3 requires confidence that performance remains consistent. The same applies when models are updated.
- Speed and confidence: Automated tests deliver higher-quality corrections across diverse documents while making me comfortable adopting model updates and exploring alternative models.
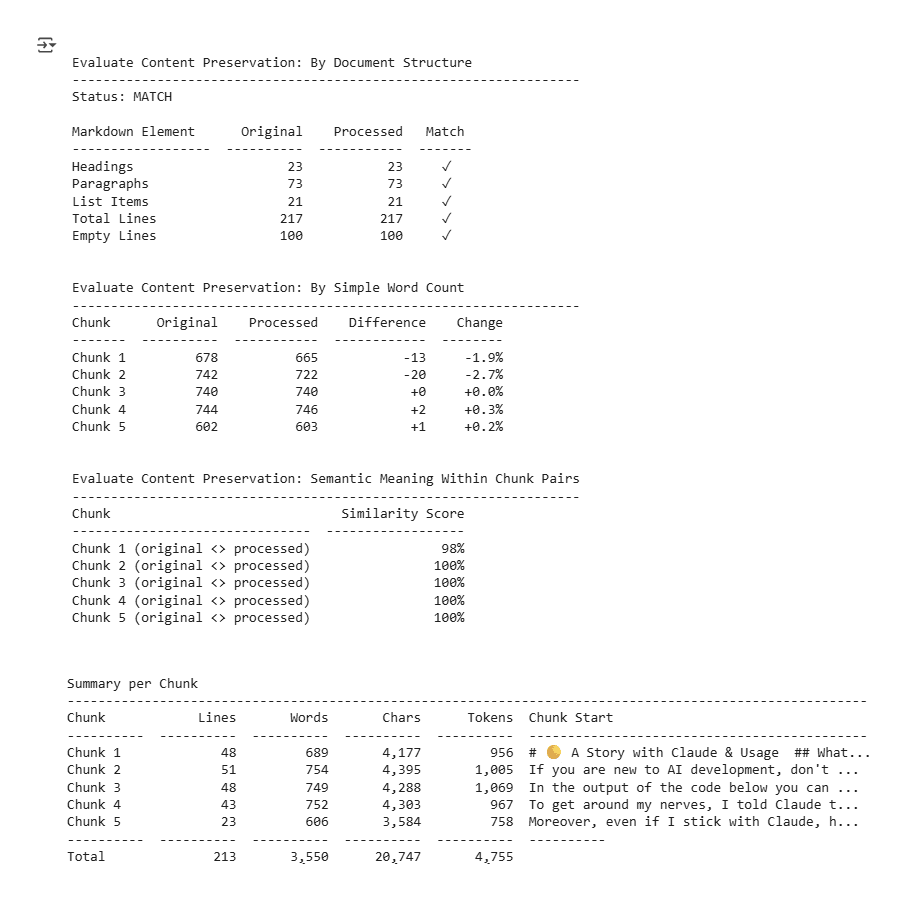
Notebook extracts on results and approach:

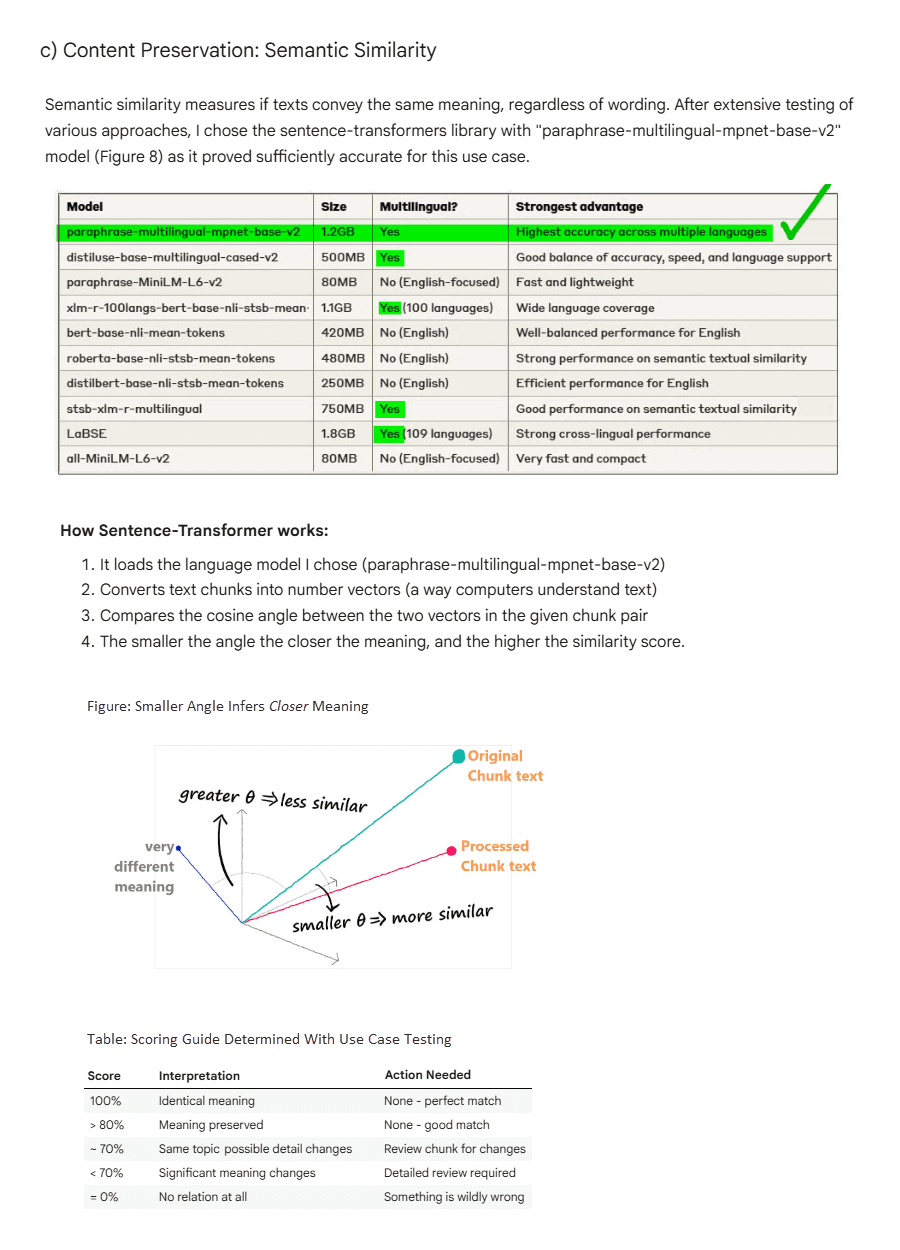
Supplementary explanation of the “semantic similarity” approach used detailed in Notebook:
Not Perfect but Aiming.
The more I learn about prompt engineering and understand how large language models work, the more imperfect my notebook becomes. For instance, the driving prompt shown below should be enhanced. Prompt chaining would allow the prompt to be broken into smaller steps, improving overall quality. Instead of repeatedly instructing Claude not to include its own comments, I could use prompt prefilling. These insights become strikingly clear with hindsight and experience.
PROMPT_TEMPLATE = """
CRITICAL: PROVIDE ONLY THE CORRECTED TEXT WITHOUT ANY ADDITIONAL COMMENTARY.
Your task is to take the provided text and rewrite it into a clear, grammatically correct version
while preserving the original meaning as closely as possible. Correct any spelling mistakes,
punctuation errors, verb tense issues, word choice problems, and other grammatical mistakes.
MANDATORY INSTRUCTIONS:
1. Determine and use the same linguistic language as the original text (e.g., English, German)
2. Preserve all existing markdown formatting, including heading levels, paragraphs, and lists
3. Make necessary grammatical corrections, including spelling, punctuation, verb tense,
word choice, and other grammatical issues. Only make stylistic changes if essential for clarity
4. Mark corrections with markdown syntax, apply one of these choices only:
- For changed text use bold: e.g., **changed** and **multiple changed words**
- For new text use bold: **new words**
- For removed text use bold strikethrough: **~~removed words~~**
5. Maintain the original structure:
- Don't add new lines of text
- Don't include additional commentary at all
- Don't convert markdown elements to different types
6. For ambiguous corrections, choose the option that best preserves original meaning and style
7. Ensure consistency in corrections throughout the text
8. Return the corrected text in markdown syntax
9. DO NOT add any explanations, introductions, or conclusions to your response
FINAL REMINDER: Your output should consist SOLELY of the corrected text.
Do not include phrases like "Here is the corrected text" or any other form of commentary.
The text to be corrected is provided between the triple tildes (~~~):
~~~
{the_markdown_chunk}
~~~
REMEMBER: Provide ONLY the corrected text without any additional words or explanations."""
Above: Core prompt driving the solution.
Conclusion
The most important lesson I learnt when building a product that leverages a large language model is to focus on the heart – automated prompt evaluation with real data. Although the solution does have this now, I could have implemented evaluations far sooner and saved a lot of time in manual prompt tweaking. It is tempting to concentrate on the whole product – but without a healthy LLM heart, there is little point.
For questions, see FAQ.