The Crux: Agentic behaviour as part of a programmatic workflow
Tools: Claude Code, FireCrawl
GitHub Project: docs-for-ai
This project automates documentation curation for AI context. It demonstrates practical agent behaviour through instructions and code – validating inputs, interpreting structured errors, and suggesting recovery paths.
What is going on with Agents
Is it agentic or just a workflow or a workflow with an agent? A definition that is “good enough” to get down to work: “Anything that I didn’t specify in code, but something happens, is an agent. There are agents of different degrees.”
What follows is a project that combines agent capabilities and deterministic coding.
A Simple Project — Docs for AI
“Docs for AI” makes it easy to curate and index documentation from websites into collections. It combines python scripts with agentic capabilities to curate a new document: “/curate-doc [collection] [URL]”. Validation happens at two levels, and both are agentic:
Level 1: Before the Script Runs. When “/curate-doc” is run, the agentic behaviour is first to sense check the collection directory and URL the user specifies.
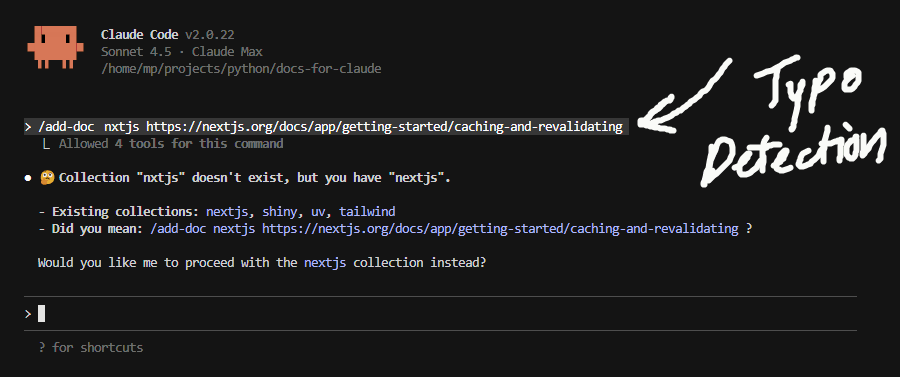
E.g. A – Typo Detection
E.g. B – Semantic Mismatch
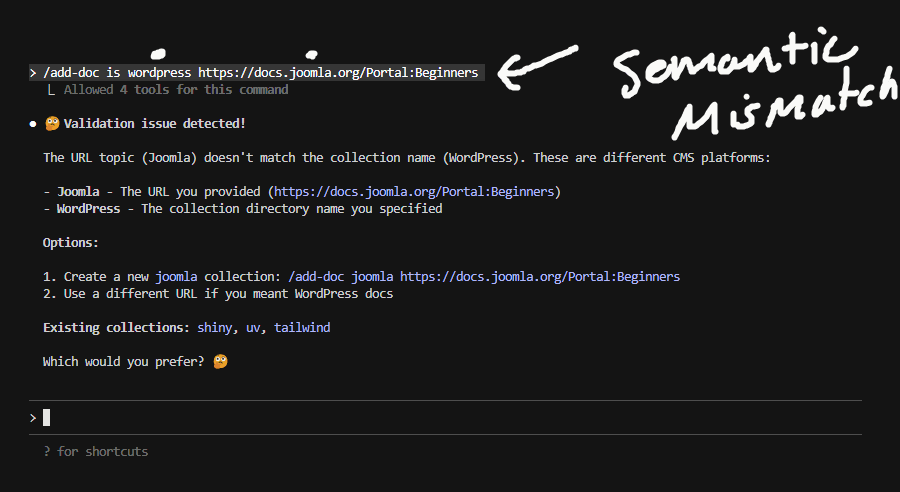
None of this was coded. In curate-doc.md, Claude Code (the agent in my case) is given context of the goal and told to be helpful to overwhelmed users. To make suggestions and await confirmation. That’s it!
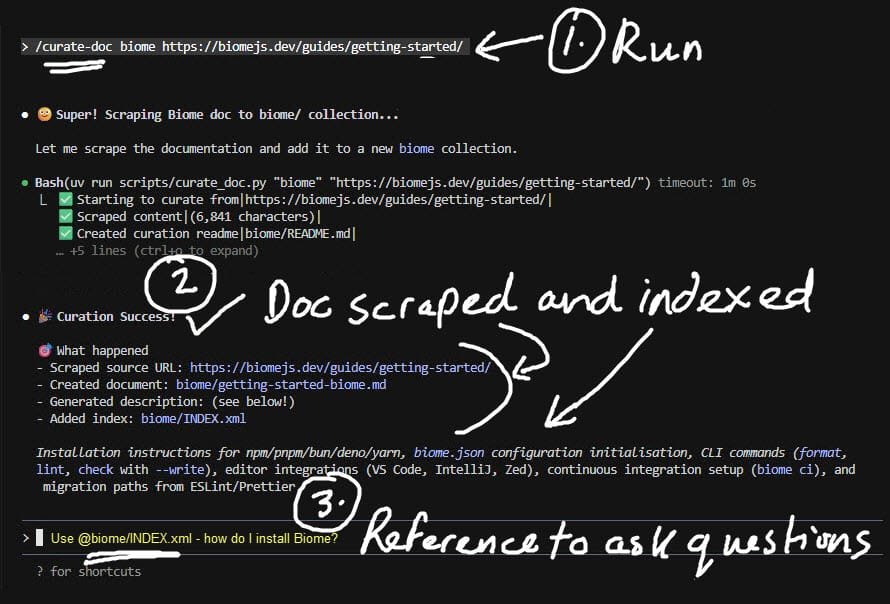
Level 2: The Script Prints Progress, Claude Code Self-Heals. When the script runs, it makes structured print statements. Here’s what the script actually outputs when it hits an error:
✅ Starting to curate from | https://tailwindcss.com/docs/hyphens |
❌ Error: INVALID_COLLECTION | Directory non-empty and missing INDEX.xml.
Rejected to prevent inadvertent file overwrites | aaa_temp |
Claude sees this structured output, interprets what went wrong, and autonomously suggests fixes and awaits user confirmation. Again, none of this was coded – Claude Code is determining what to suggest given the context.
Finally, When Things Go Right, the script output looks like this:
✅ Starting to curate from | https://nextjs.org/docs/app/getting-started/images |
✅ Scraped content | (12,847 characters) |
✅ Written scrape to file | nextjs/getting-started-image-optimization-nextjs.md |
✅ Updated index | nextjs/INDEX.xml |
💡 INDEX.xml <description> pending: PLACEHOLDER requires summary |
🎉 Curation Success! | scraped, created and indexed new document |
Then Claude reads the scraped markdown and writes a semantic description of the document into `nextjs/INDEX.xml`:
<description>
Details Next.js Image component features including automatic
optimisation, lazy loading, local and remote image handling, and
remote patterns configuration for secure image sources.
</description>
Summarisation is basic LLM work. What’s agentic: interpreting the script output and knowing exactly where to update INDEX.xml.
Lessons Learnt
Despite a simple use case, these lessons carry through to more complex use cases:
| 📝 Clear instructions are HARD | Simplicity is difficult, less is powerfully more. It is an iterative path to get there. |
| 🎯 Examples need balance | Just enough gives you predictability, too much and you limit the agent’s flexibility |
| ⚠️ Agents suggest nonsensical things | For example, “Directory has other files, shall I delete it and continue?”. So although you don’t need to code every edge case, you must now guardrail agent suggestions. |
| 🧠 Thinking changes behaviour | Choose one mode and stick with it or double your work and test both. |
| ✨ Structured output wins | Detailed easy-to-parse print statements enable the agent’s self-healing capabilities |
| 🤝 Agents are great for UX | It’s difficult to predict what your users do. An agent can provide a personalised experience that is for more helpful than a standard error message. |
The Two-Level Pattern:
• Level 1: Validates Arguments → Suggests Correction → Awaits Confirmation
• Level 2: Script Runs → Prints Progress → Claude Detects Errors → Suggests Fix
Appendix I — Why This Pattern Works
The two slash commands in this project balance scripts (deterministic reliability) with agent reasoning (intelligent adaptation). Scripts handle the scraping mechanics. Agents handle validation logic, error interpretation, and semantic description generation. Neither alone would work – scripts can’t infer intent, agents can’t reliably scrape at scale. Together they’re surprisingly effective even for this simple use-case. Why effective? It has saved me hours in scraping docs for AI context.
For further details see GitHub Project README.md
Appendix II — The Reality of Agents from Zapier
Wade Foster (Zapier CEO) articulates what this project demonstrates: most impressive AI systems today occupy the middle ground between pure workflows and pure agents. His observation that “most people asking for agents actually want workflows” resonates – knowing where to draw the deterministic/agentic line matters more than making everything agentic. The conversation reinforces that constrained, focused agent tasks within structured workflows outperform general-purpose agents for production use.
Appendix III — Spawning Agents Dynamically To “Research and Evaluate”
Everything seems to be an agent. here is an example of getting Claude Code to create six copies of itself, operate each in a different context, and then come back to synthesise the findings into one report for me. The benefits being it’s quicker than in sequence and you don’t need to keep opening new terminals when the context overflows. Other than that, I don’t know.
# Next.js 16 Project: Best Practices Evaluation
## Context
This Next.js 16 project uses: Biome, GitHub Actions, Lefthook, Playwright.
Only functionality added beyond base Next.js 16 installation is an about page.
Analyse @README.md. For CI, GitHub Branch rule set exists at `@rule-set.json`.
## Task
Evaluate this project against modern best practices for each tool. Research official
documentation, analyse my implementation, and report findings with recommendations.
## Approach: Use Sub-Agents (dynamically spawn via Task tool)
Spawn 6 focused sub-agents:
- `biome-expert` - Biome configuration and CI integration
- `playwright-expert` - Testing setup
- `github-actions-expert` - CI/CD pipeline using Git Actions and Git Workflow
- `lefthook-expert` - Git hooks (web search needed)
- `nextjs-expert` - Next.js 16 best practices for CI and Playwright
## Research Process
**For Each Sub-Agent:**
1. **Research**: Read `/home/mp/projects/python/docs-for-ai/README.md` table
to find relevant INDEX.xml files. Identify and read applicable documentation.
2. **Analyse**: Use Grep/Glob to find relevant project files. Compare implementation
against best practices.
3. **Report**: Write findings to `temp3/[technology]-evaluation.md` with:
- Critical issues (fix now)
- Important improvements (fix soon)
- Recommended enhancements (nice to have)
- Specific file paths and line numbers
- Actionable recommendations with examples
4. **Summarise**: Return concise summary to main agent.
## Final Deliverable
Synthesise all sub-agent findings into `temp3/report3.md` containing:
- Executive summary with overall compliance score
- Per-technology findings
- Prioritised recommendations roadmap
- Cross-cutting concerns
## Constraints
- **DO NOT** make any code changes - evaluation only
- **DO** ask clarifying questions before proceeding
- **DO** research local docs first, web search only for gaps
- **DO** provide specific file paths, line numbers, and code examples